
Nvidia’s New Chip Shows Its Muscle in AI Tests

It’s time for the “Olympics of machine learning” yet again, and if you are fatigued of viewing Nvidia at the prime of the podium in excess of and more than, much too negative. At least this time, the GPU powerhouse put a new contender into the mix, its Hopper GPU, which delivered as much as 4.5 instances the performance of its predecessor and is due out in a issue of months. But Hopper was not by yourself in making it to the podium at MLPerf Inferencing v2.1. Techniques primarily based on Qualcomm’s AI 100 also produced a good exhibiting, and there ended up other new chips, new types of neural networks, and even new, much more practical strategies of testing them.
Ahead of I go on, let me repeat the canned reply to “What the heck is MLPerf?”
MLPerf is a set of benchmarks agreed upon by customers of the industry team MLCommons. It is the initial attempt to deliver apples-to-apples comparisons of how excellent computer systems are at teaching and executing (inferencing) neural networks. In MLPerf’s inferencing benchmarks, techniques made up of combinations of CPUs and GPUs or other accelerator chips are tested on up to 6 neural networks that perform a wide range of widespread functions—image classification, item detection, speech recognition, 3D healthcare imaging, natural-language processing, and suggestion. The networks had by now been educated on a normal established of information and had to make predictions about knowledge they experienced not been uncovered to ahead of.
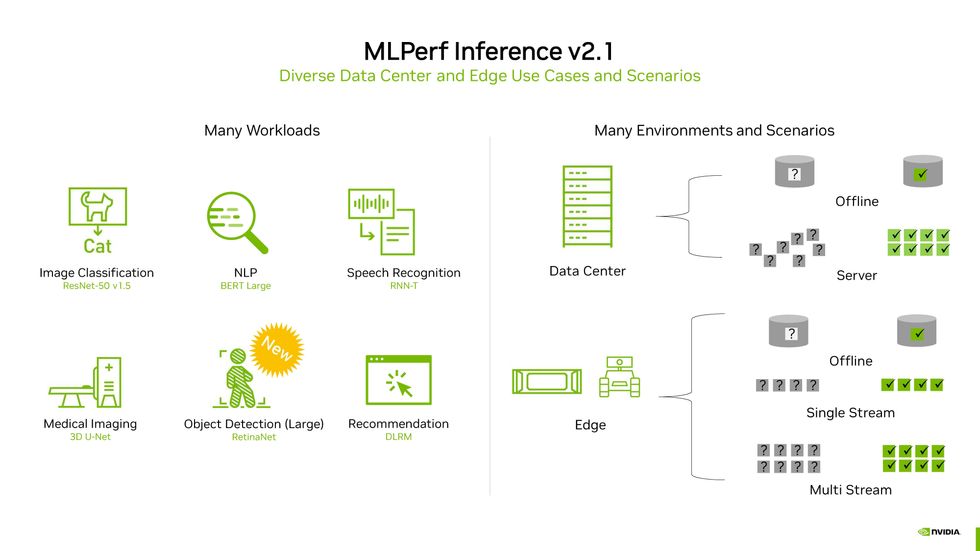
This slide from Nvidia sums up the entire MLPerf energy. Six benchmarks [left] are examined on two types of personal computers (details heart and edge) in a assortment of disorders [right].Nvidia
Examined personal computers are categorized as supposed for data facilities or “the edge.” Commercially out there data-centre-based methods were being analyzed beneath two conditions—a simulation of serious details-centre exercise wherever queries get there in bursts and “offline” activity wherever all the data is available at once. Desktops intended to do the job on-web site instead of in the data center—what MLPerf phone calls the edge, due to the fact they’re positioned at the edge of the network—were calculated in the offline state as if they ended up receiving a solitary stream of facts, this sort of as from a protection camera and as if they experienced to cope with numerous streams of details, the way a automobile with several cameras and sensors would. In addition to tests raw performance, computers could also compete on performance.
The contest was further divided into a “closed” classification, in which every person experienced to run the exact “mathematically equivalent” neural networks and satisfy the exact same accuracy measures, and an “open” category, the place companies could show off how modifications to the standard neural networks make their methods get the job done much better. In the contest with the most effective computers underneath the most stringent situations, the shut facts-center team, computer systems with AI accelerator chips from four organizations competed: Biren, Nvidia, Qualcomm, and Sapeon. (Intel manufactured two entries with no any accelerators, to exhibit what its CPUs could do on their have.)
Though quite a few units had been examined on the full suite of neural networks, most results were being submitted for graphic recognition, with the all-natural-language processor BERT (shorter for Bidirectional Encoder Representations from Transformers) a close 2nd, building people groups the least complicated to examine. Many Nvidia-GPU-centered programs ended up tested on the whole suite of benchmarks, but accomplishing even a single benchmark can acquire additional than a month of operate, engineers included say.
On the impression-recognition demo, startup Biren’s new chip, the BR104, executed very well. An 8-accelerator personal computer built with the company’s companion, Inspur, blasted through 424,660 samples for each 2nd, the fourth-swiftest process tested, driving a Qualcomm Cloud AI 100-centered machine with 18 accelerators, and two Nvidia A100-primarily based R&D units from Nettrix and H3C with 20 accelerators every.
But Biren definitely showed its energy on organic-language processing, beating all the other 4-accelerator devices by at minimum 33 % on the best-accuracy edition of BERT and by even even larger margins amid eight-accelerator devices.
An Intel procedure based on two shortly-to-be-introduced Xeon Sapphire Rapids CPUs with no the aid of any accelerators was an additional standout, edging out a equipment applying two recent-technology Xeons in mixture with an accelerator. The big difference is partly down to Sapphire Rapids’ Superior Matrix Extensions, an accelerator worked into every single of the CPU’s cores.
Sapeon introduced two programs with distinct versions of their Sapeon X220 accelerator, screening them only on graphic recognition. Each handily defeat the other single-accelerator desktops at this, with the exception of Nvidia’s Hopper, which got through six moments as much get the job done.
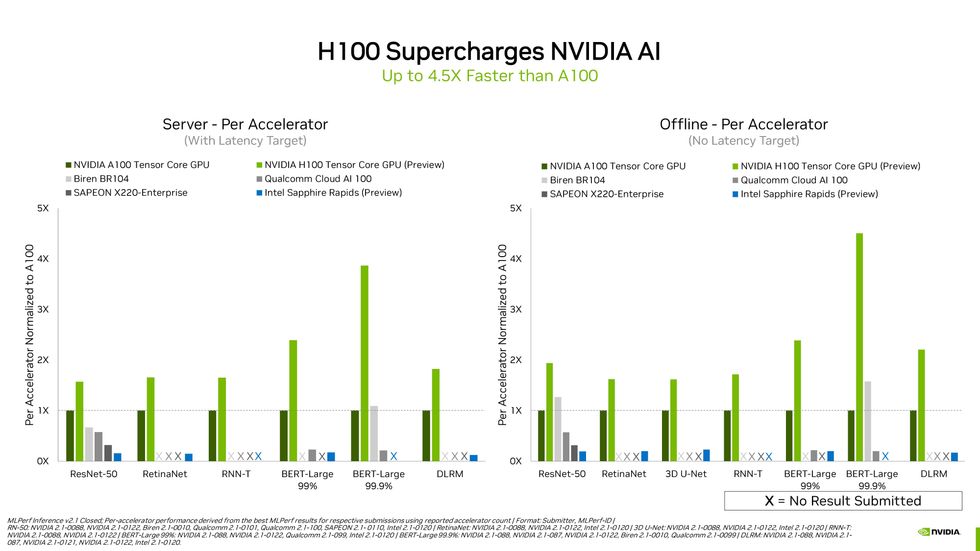
Computers with multiple GPUs or other AI accelerators generally operate speedier than people with a solitary accelerator. But on a for every-accelerator foundation, Nvidia’s future H100 very considerably crushed it.Nvidia
In truth, among the methods with the same configuration, Nvidia’s Hopper topped just about every category. As opposed to its predecessor, the A100 GPU, Hopper was at least 1.5 times and up to 4.5 moments as rapidly on a for each-accelerator foundation, depending on the neural network under check. “H100 arrived in and truly introduced the thunder,” says Dave Salvator, Nvidia’s director of product internet marketing for accelerated cloud computing. “Our engineers knocked it out of the park.”
Hopper’s not-solution-at-all sauce is a technique known as the transformer engine. Transformers are a class of neural networks that consist of the purely natural-language processor in the MLPerf inferencing benchmarks, BERT. The transformer motor is intended to speed inferencing and teaching by modifying the precision of the quantities computed in each layer of the neural network, making use of the minimum wanted to attain an accurate final result. This contains computing with a modified variation of 8-bit floating-level quantities. (Here’s a extra comprehensive explanation of minimized-precision equipment learning.)
For the reason that these success are a very first attempt at the MLPerf benchmarks, Salvator says to expect the gap among H100 and A100 to widen, as engineers learn how to get the most out of the new chips. There is superior precedence for that. As a result of application and other advancements, engineers have been in a position to pace up A100 devices constantly due to the fact its introduction in May 2020.
Salvator states to count on H100 outcomes for MLPerf’s efficiency benchmarks in upcoming, but for now the business is targeted on observing what kind of efficiency they can get out of the new chip.
Effectiveness
On the efficiency entrance, Qualcomm Cloud AI 100-based machines did on their own proud, but this was in a much smaller industry than the efficiency contest. (MLPerf reps stressed that desktops are configured in a different way for the performance assessments than for the general performance assessments, so it’s only good to review the efficiency of programs configured to the exact same intent.) On the offline image-recognition benchmark for facts-centre methods, Qualcomm took the top rated 3 spots in conditions of the amount of photos they could acknowledge per joule expended. The contest for effectiveness on BERT was substantially nearer. Qualcomm took to the prime spot for the 99-per cent-accuracy version, but it lost out to an Nvidia A100 system at the 99.99-%-precision process. In both equally situations the race was near.
The situation was identical for impression recognition for edge techniques, with Qualcomm getting almost all the leading spots by working with streams of knowledge in fewer than a millisecond in most conditions and often applying much less than .1 joules to do it. Nvidia’s Orin chip, owing out within just 6 months, arrived closest to matching the Qualcomm benefits. Once more, Nvidia was superior with BERT, applying less vitality, nevertheless it nonetheless couldn’t match Qualcomm’s velocity.
Sparsity
There was a whole lot going on in the “open” division of MLPerf, but 1 of the additional attention-grabbing success was how businesses have been displaying how very well and effectively “sparse” networks complete. These consider a neural community and prune it down, eradicating nodes that lead tiny or absolutely nothing toward developing a consequence. The substantially more compact network can then, in idea, operate faster and much more effectively even though utilizing fewer compute and memory resources.
For illustration, startup Moffett AI confirmed results for a few computer systems utilizing its Antoum accelerator architecture for sparse networks. Moffett examined the programs, which are meant for data-center use on picture recognition and all-natural-language processing. At graphic recognition, the company’s commercially offered process managed 31,678 samples for each second, and its coming chip hit 95,784 samples for every next. For reference, the H100 hit 95,784 samples for every 2nd, but the Nvidia equipment was functioning on the entire neural community and satisfied a bigger precision goal.
Yet another sparsity-focused organization, Neural Magic, confirmed off computer software that applies sparsity algorithms to neural networks so that they operate a lot quicker on commodity CPUs. Its algorithms decreased the size of a variation of BERT from 1.3 gigabytes to about 10 megabytes and boosted throughput from about 10 samples per 2nd to 1,000, the enterprise claims.
And last but not least, Tel Aviv-primarily based Deci employed software package it calls Automatic Neural Architecture Design technologies (AutoNAC) to make a edition of BERT optimized to operate on an AMD CPU. The resulting community sped throughput additional than sixfold using a model that was just one-3rd the dimensions of the reference neural community.
And Additional
With extra than 7,400 measurements across a host of classes, there is a good deal extra to unpack. Truly feel cost-free to choose a seem on your own at MLCommons.


